
Coordonner plusieurs agents autonomes pour qu’ils atteignent un objectif commun est l’un des défis centraux de l’intelligence artificielle moderne. Cette problématique, appelée prise de décision coopérative multi-agent (multi-agent cooperative decision-making), concerne autant les robots collaboratifs que les voitures autonomes ou les agents conversationnels.
Dans une synthèse récente, des chercheurs de l’université Jiaotong de Xi’an, de l’université de Hong Kong et d'Imperial College London dressent un état des lieux de ce champ de recherche. L’article pré-publié recense les principales approches, les plateformes de simulation utilisées et les domaines d’application, tout en proposant une taxonomie précise des méthodes fondées sur l’apprentissage par renforcement ou les modèles de langage.
Cinq familles d’approches
Les auteurs distinguent cinq grandes catégories d’approches pour structurer la coopération entre agents : les méthodes fondées sur des règles (notamment la logique floue) ; celles issues de la théorie des jeux ; les algorithmes évolutionnaires ; l’apprentissage par renforcement multi-agent (Multi-Agent Reinforcement Learning, Marl) et, enfin, les systèmes fondés sur des modèles de langage (LLM-based MAS).
Les trois premières approches – règles, jeux et évolution – reposent sur des stratégies préconçues. Elles ont montré leurs limites dans des environnements dynamiques et l’attention se concentre désormais sur les deux dernières. Les méthodes Marl et LLM-based MAS permettent en revanche aux agents d’apprendre de leurs interactions et de s’adapter à des contextes changeants, avec ou sans supervision humaine directe.
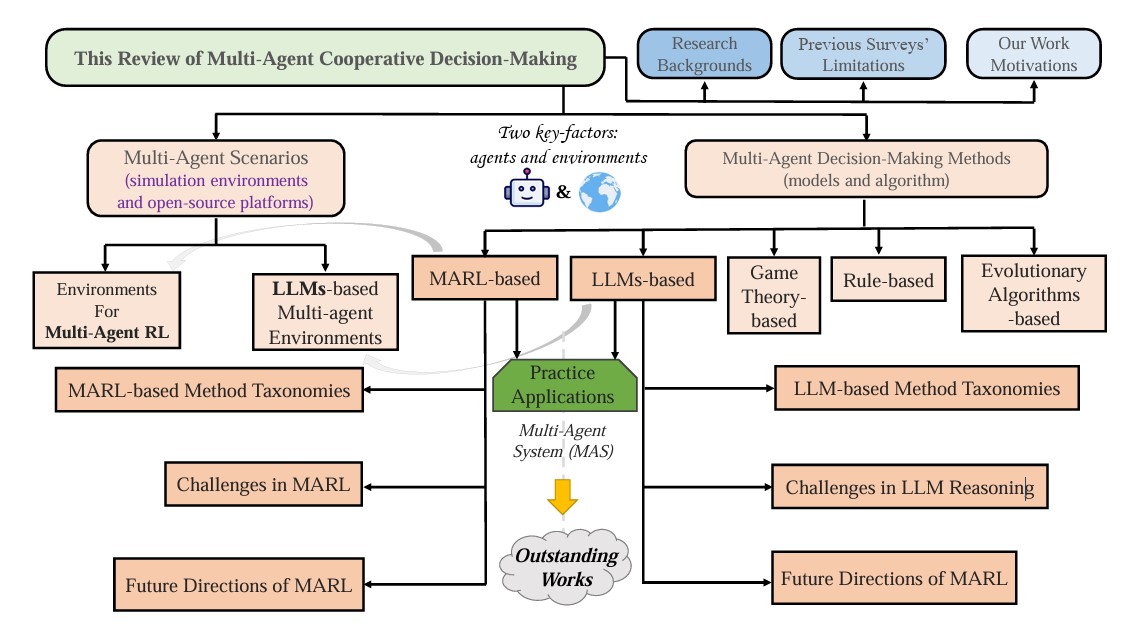
Illustration de la revue systématique de la recherche sur la prise de décision intelligente multi-agents. • Weiqiang Jin et al.
Trois paradigmes d’apprentissage
Le champ Marl se structure autour de trois paradigmes. Le premier, CTCE (centralized training and execution), repose sur un contrôle centralisé des agents. Le second, DTDE (decentralized training and execution), laisse chaque agent s’entraîner et agir de manière indépendante, ce qui favorise l’évolutivité mais limite la coordination.
Le paradigme dominant est aujourd’hui hybride : le CTDE (centralized training and decentralized execution). Les agents sont entraînés de manière centralisée mais exécutent leur politique de façon autonome. Cette architecture hybride résout certains problèmes structurels du Marl, comme la non-stationnarité de l’environnement ou l’attribution du mérite à chaque agent dans un succès collectif.
Vers des systèmes gouvernés par le langage
Depuis l’émergence des grands modèles de langage, une nouvelle famille d’approches s’est développée. Dans ces systèmes multi-agents (MAS) basés sur des LLM, chaque agent peut dialoguer, planifier, déléguer ou négocier avec les autres par le biais du langage. Un agent principal élabore un plan global, que les agents secondaires exécutent tout en transmettant des retours ou en demandant des ajustements.
Ces systèmes sont utilisés dans des applications variées : collaboration entre robots, jeux stratégiques, assistance distribuée, planification multimodale ou simulation d’interactions sociales. Plusieurs frameworks open source (AutoGen, CrewAI, LangGraph) permettent déjà de mettre en place ce type de coordination.
De nouveaux environnements de test
Le papier consacre une large part à l’analyse des environnements de simulation utilisés pour tester ces méthodes. Du côté Marl, on trouve des plateformes comme MAgent (scénarios avec des centaines d’agents), StarCraft II (tâches coopératives en temps réel), ou Google Football. Du côté LLM-based MAS, les environnements sont plus narratifs ou multimodaux, comme CuisineWorld (collaboration en cuisine), AgentScope (environnements multi-sensoriels) ou Generative Agents (simulation sociale dans un monde virtuel).
Chaque environnement favorise des compétences spécifiques : planification spatiale, communication ciblée, coordination stratégique ou adaptation dynamique. La maîtrise de ces terrains d’entraînement conditionne la robustesse des agents en situation réelle.
Des usages de plus en plus larges
Les méthodes recensées sont déjà appliquées à la logistique, la navigation autonome, la gestion du trafic, la robotique collaborative, les jeux complexes ou la simulation économique. Les modèles Marl sont testés dans des missions de sauvetage, des configurations militaires ou des réseaux d’énergie distribués. Les systèmes à base de LLM sont employés pour modéliser des comportements sociaux, simuler des marchés ou structurer la coopération entre logiciels.
L’étude détaille plusieurs innovations récentes, comme l’intégration du raisonnement en langage naturel dans l’apprentissage, la communication adaptative entre agents, ou l’emploi de mesures d’information mutuelle pour améliorer la coordination. Ces techniques renforcent la flexibilité des agents dans des environnements incertains.
Des défis encore ouverts
Les auteurs identifient plusieurs obstacles. D’abord, le passage à l’échelle reste difficile : la coordination de dizaines, voire de centaines d’agents, pose des problèmes de communication et d’attribution du mérite. Ensuite, la plupart des modèles manquent de transparence : il est encore difficile de comprendre pourquoi un système multi-agent adopte telle stratégie plutôt qu’une autre.
Enfin, peu de travaux abordent la robustesse aux perturbations extérieures (bruit, défaillance d’un agent, changement d’objectif), ni l’alignement des agents avec des valeurs humaines, notamment dans les systèmes ouverts. Pour les auteurs, l’avenir du domaine dépendra autant de l’inventivité algorithmique que de la qualité des environnements, des cadres d’évaluation et des interfaces avec les utilisateurs humains.
Pour en savoir plus :
- Weiqiang Jin et al., A Comprehensive Survey on Multi-Agent Cooperative Decision-Making: Scenarios, Approaches, Challenges and Perspectives, Arxiv, 2025