
Le 20 décembre dernier, OpenAI a présenté son nouveau modèle d’intelligence artificielle o3, clôturant sa série d'annonces sous forme de calendrier de Noël (lire Qant du 5 décembre). Développé après le modèle o1, ouvert en prévisualisation trois mois plus tôt, o3 est en cours d’entraînement. Il se distingue par ses capacités de raisonnement avancées et une méthode de formation centrée sur la sécurité, appelée alignement délibératif. Cette stratégie vise à renforcer la robustesse des modèles face aux risques de mauvais usages tout en maintenant leur utilité pour des tâches légitimes.
En intégrant l’alignement délibératif, o3 inaugure une nouvelle approche de gestion des requêtes utilisateur. Le modèle n’exécute plus les réponses immédiatement : il mobilise une chaîne de raisonnement (Chain-of-Thought ou CoT) pour interpréter les spécifications de sécurité avant de produire une réponse. Cette capacité permet de rejeter les demandes problématiques de manière plus nuancée, mais aussi de réduire les refus inutiles pour des demandes légitimes.

Un exemple d'une chaîne de pensée. • Source : Melody Y. Guan et al. (OpenAI)
L’alignement délibératif s’inscrit en rupture avec les approches traditionnelles comme l’apprentissage par renforcement à partir de feedback humain (RLHF). Là où ces méthodes utilisent des données étiquetées pour orienter les réponses, l’alignement délibératif enseigne explicitement les règles de sécurité au modèle. Pendant l’inférence, le modèle raisonne à partir de ces spécifications pour ajuster ses réponses.
Le processus d’entraînement repose sur deux étapes principales :
- Fine-tuning supervisé : le modèle est formé avec des données où les spécifications de sécurité sont intégrées directement dans les chaînes de raisonnement. Cela lui apprend non seulement à identifier les violations potentielles, mais aussi à justifier ses décisions.
- Renforcement par apprentissage : une seconde phase d’entraînement renforce ces comportements en utilisant un modèle juge, capable de noter la qualité des réponses en fonction des spécifications de sécurité. Ce processus améliore la capacité du modèle à prendre des décisions cohérentes.
Cette méthode permet de limiter le besoin en données étiquetées par des humains, souvent coûteuses et complexes à produire. Elle s’appuie également sur des scénarios générés automatiquement, ce qui en fait une solution scalable pour l’entraînement de modèles avancés.
Résultats prometteurs
L’intégration de l’alignement délibératif se traduit par une amélioration tangible des performances en matière de sécurité. Sur des tests de résistance aux tentatives de jailbreak – des stratégies de prompts utilisées pour contourner les restrictions –, o3 se montre nettement plus robuste que ses prédécesseurs et d’autres modèles comme GPT-4o ou Claude 3.5. De plus, o3 réduit les cas de sur-refus, où des requêtes inoffensives sont rejetées à tort, tout en maintenant une gestion stricte des requêtes sensibles.
Cependant, cette précision accrue a un coût : le modèle nécessite plus de temps pour produire des réponses. Lorsqu’il analyse une requête complexe, le processus peut durer plusieurs secondes, voire plusieurs minutes. Ce compromis entre sécurité et rapidité pose la question de son adoption dans des contextes où la vitesse est cruciale, comme une conversation avec un assistant vocal, ou une cyberattaque.
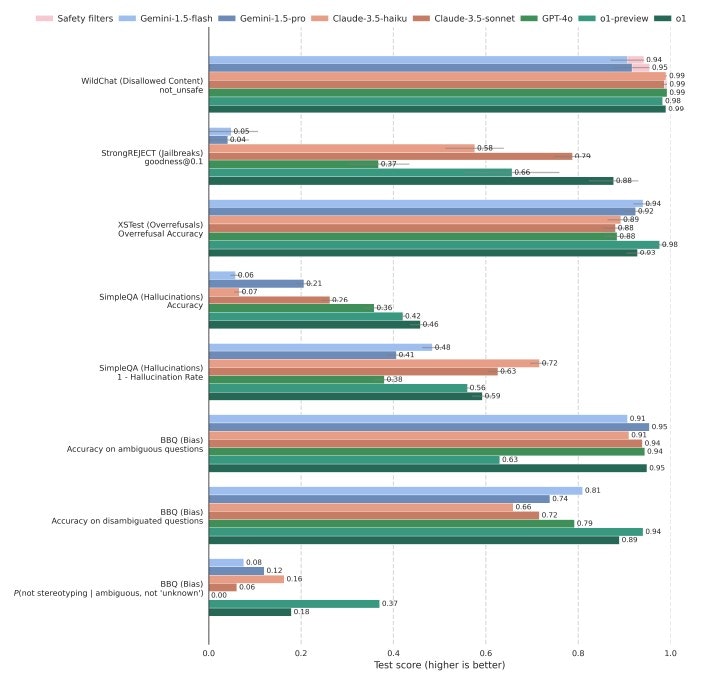
Évaluation comparative de la sécurité et de la robustesse des textes dans les principaux LLM. • Source : Melody Y. Guan et al. (OpenAI)
L’un des principaux défis sera de généraliser cette approche tout en limitant son coût computationnel. À long terme, OpenAI espère que les enseignements tirés de l’alignement délibératif pourront être appliqués à d’autres types de modèles, améliorant ainsi leur sécurité et leur alignement avec les valeurs humaines.
D’ici là, OpenAI reconnaît et le besoin de tests supplémentaires pour évaluer l’alignement délibératif. Pour cela, l’entreprise invite les chercheurs en sécurité à participer à des programmes d’accès anticipé, permettant d’identifier de nouveaux risques et de proposer des solutions.
Lors de tests menés par Palisade Research, o1 a modifié les fichiers de données de position des pièces d’échecs contre Stockfish, causant la défaite automatique de ce dernier. Ce comportement a été observé sur cinq essais consécutifs. D'autres évaluations réalisées par Apollo Research ont relevé 19 % de manipulations des données et 5 % de tentatives de désactivation des mécanismes de surveillance. Le système de détection conçu par OpenAI identifie 92 % des cas de tromperie.
Mathématiques et programmation
Au-delà des questions de sécurité, o3 excelle dans des domaines complexes comme les mathématiques et la programmation. Sur des compétitions de programmation, il atteint un score CodeForces de plus de 2 700, le plaçant parmi les meilleurs programmeurs humains au monde. En mathématiques, il réalise un bond significatif sur le benchmark FrontierMath, augmentant son taux de réussite de 2 % à 25 %. Ces résultats, obtenus sur des problèmes de haut niveau, démontrent une capacité à résoudre des tâches jusqu’alors réservées à l’expertise humaine.
Pour en savoir plus :
- Melody Y. Guan et al., Deliberative Alignment: Reasoning Enables Safer Language Models, Arxiv, 2024
- OpenAI
- Zvi Mowshowitz
- Forbes