")
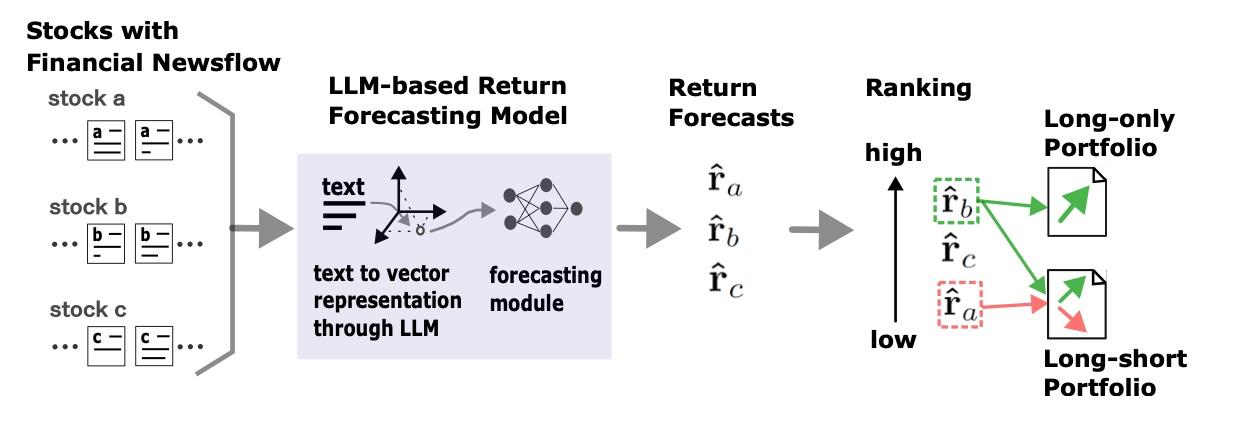
En juillet dernier, Tian Guao et Emmanuel Hauptmann, de la société de gestion suisse RAM AI, ont montré dans Fine-Tuning Large Language Models for Stock Return Prediction Using Newsflow (Arxiv, juil. 24), une stratégie d’investissement fondée sur l’analyse du newsflow par des LLM. Les représentations que se forment les modèles d’IA à partir des actualités aboutissent à un classement et des décisions d’investissement.
Plus généralement, leur article explore l'utilisation des grands modèles de langage (LLM) pour prédire les rendements des actions à partir de flux d'actualités financières. Le but principal est de démontrer comment le réglage fin (finetuning) des LLM peut améliorer les performances des portefeuilles d'investissement en exploitant les informations sémantiques extraites des actualités. Les auteurs comparent deux modèles encodeur-seul, Llama3-8b et Mistral-7b, et un décodeur-seul, DeBertha de Microsoft.
Les résultats de l'étude, réalisée sur des données réelles, suggèrent que l'approche de prédiction basée sur les LLM surpasse les scores de sentiment traditionnels et que les représentations agrégées contribuent généralement à des prédictions de rendement plus précises. L'article souligne également que le choix du modèle LLM et de la méthode de représentation peut influencer les performances. Des trois modèles examinés, Mistral-7b affiche une robustesse accrue dans des univers d'investissement de grande taille.
Tian Guao et Emmanuel Hauptmann corroborent ainsi un article signé en avril par une équipe de chercheurs de deux universités singapouriennes. Avec Financial Sentiment Analysis: Techniques and Applications, Kelvin Du et ses collègues proposent un bon récapitulatif de la problématique de l’analyse du sentiment des investisseurs, plus complexe à faire qu’à dire.
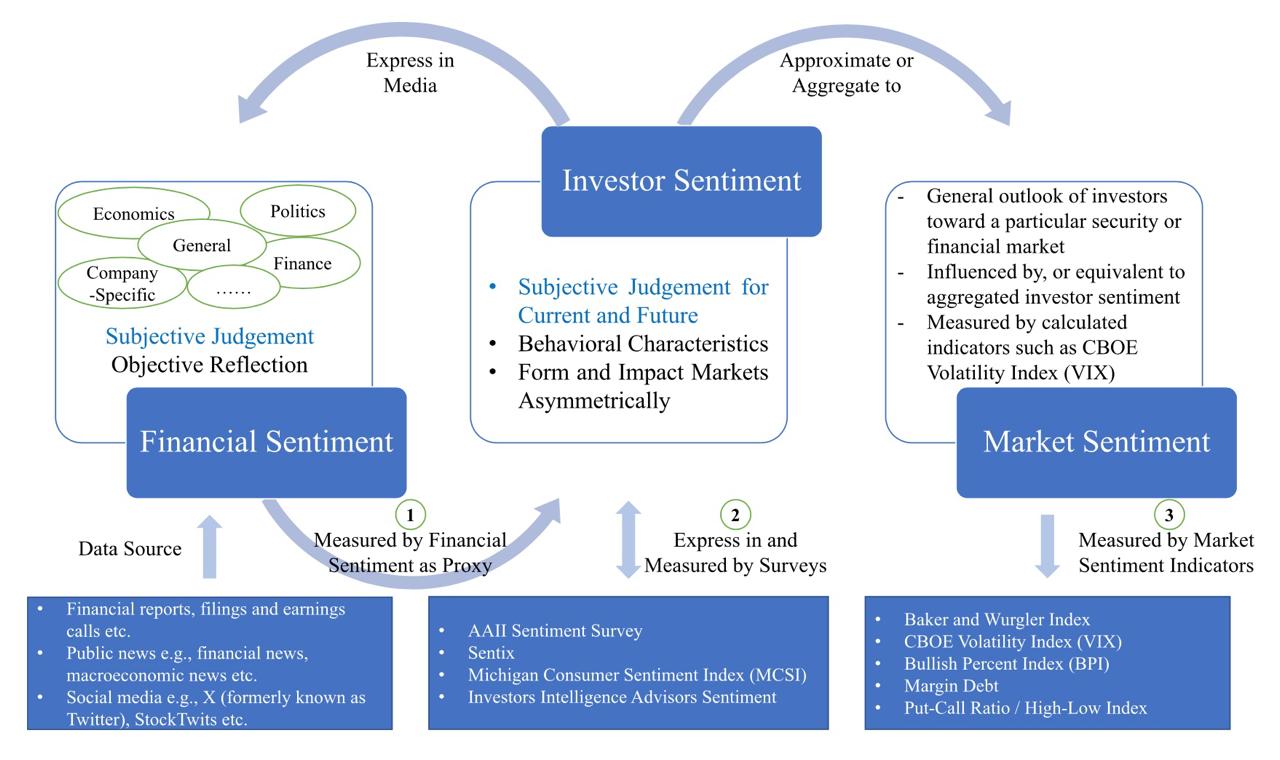
La structure de l’analyse de sentiment en finance.
Leur article passe en revue les algorithmes de machine learning utilisés pour l’analyse de sentiment financier (FSA) – Bagging, Random Forest, AdaBoost, GB, Lasso, Support Vector Regression (SVR), XGB – et les modèles adoptés sur les réseaux neuronaux convolutifs et récurrents, ainsi que les démarches hybrides. Et, surtout, les modèles de langage pré-entraînés, notamment les Bert (Bidirectional Encoder Representations from Transformers), et quelques modèles récents comme Bloomberg-GPT (lire Qant du 7 avril 2023).
Il s’arrête cependant là, alors que l’équipe de Tianming Liu, à l’université de Géorgie aux États-Unis, les examinait dès janvier, dans Revolutionizing Finance with LLMs: An Overview of Applications and Insights.
Source : Tianming Liu et al., Revolutionizing Finance with LLMs: An Overview of Applications and Insights, Arxiv 2024
Transformer l'analyse en prédiction
Or, à lire ces études récentes, on peut réellement considérer que les modèles de langage de grande taille (LLM) révolutionnent l'analyse des flux d'actualités financières pour la prédiction des rendements, en passant d'un processus d'extraction de caractéristiques et de validation conventionnel à une prédiction directe des informations aux rendements.
Traditionnellement, l'analyse des sentiments financiers reposait sur l'identification et la validation de la relation entre les caractéristiques extraites, telles que le sentiment financier, et les rendements. Cependant, les LLM peuvent générer des représentations numériques de texte qui capturent les relations sémantiques. Ces représentations servent de caractéristiques pour les tâches de prévision. En analysant un plus large éventail de sources de données, les LLM peuvent offrir des prédictions plus précises que les méthodes traditionnelles basées uniquement sur des données numériques.
En outre, l'intégration de l'analyse de données textuelles fournit une compréhension plus globale de la dynamique du marché, avec une capacité d’adaptation rapide aux nouvelles informations et à l'évolution des scénarios de marché. Mais les LLM peuvent aussi être adaptés pour se concentrer sur des secteurs, des régions ou des types de données spécifiques.
De l’information à l’action
En résumé, ce nouveau processus implique la conversion des données de flux d'actualités en prédictions de rendement via un modèle de prédiction de rendement basé sur un LLM. Le LLM est entraîné pour établir une relation directe entre les nouvelles financières et les performances futures des actions en utilisant le texte des actualités et le rendement futur comme entrées d'entraînement.
Les portefeuilles construits à l'aide de prédictions de rendement basées sur des représentations de texte de LLM surpassent les portefeuilles construits à l'aide de scores de sentiment conventionnels. De plus, l'intégration de la capacité de traitement de texte des LLM et des algorithmes de trading quantitatifs sophistiqués a le potentiel d'améliorer encore les stratégies de trading. Cependant, les LLM sont plus efficaces dans l'analyse de données textuelles que dans l'exécution de calculs directs : leur utilité dans des tâches comme l'optimisation et le trading quantitatif reste limitée.
Pour l’instant.
Pour en savoir plus :
- Tian Guao, Emmanuel Hauptmann, Fine-Tuning Large Language Models for Stock Return Prediction Using Newsflow, Arxiv (juil. 24)
- Rui Mao et al, Financial Sentiment Analysis: Techniques and Applications, ACM Comput. Surv. 56, 9, Article 220 (avril 24)
- Tianming Liu et al., Revolutionizing Finance with LLMs: An Overview of Applications and Insights, Arxiv (jan. 24)
- Ankur Sinha et al, SEntFiN 1.0: Entity‐aware sentiment analysis for financial news, Journal of the Association for Information Science & Technology, vol. 73(9), pages 1314-1335, (Sept. 22)