
La génération automatique de musique, et plus particulièrement de chansons comprenant à la fois des paroles et un accompagnement instrumental, reste un défi technique important. Les approches existantes adoptent généralement des modèles à plusieurs étapes, où la synthèse vocale et l'accompagnement musical sont traités séparément avant d'être fusionnés. Cette stratégie se traduit par des processus d'apprentissage et d'inférence complexes et parfois rigides. L'équipe de chercheurs à l'origine de SongGen propose une alternative avec un modèle en une seule étape, qui vise à produire simultanément la voix et l'accompagnement.
SongGen repose sur un transformer auto-régressif intégrant plusieurs paramètres permettant de contrôler la génération : texte des paroles, instruments, genre musical, ambiance et timbre de voix. Une fonctionnalité de clonage vocal est également incluse, permettant d'utiliser un extrait audio de trois secondes comme référence. Le modèle propose deux modes de sortie : un mode mixte, où les voix et l'accompagnement sont fusionnés en un seul fichier audio, et un mode bi-piste, où chaque composante est générée séparément pour faciliter le travail en post-production.
Un modèle basé sur un transformeur auto-régressif
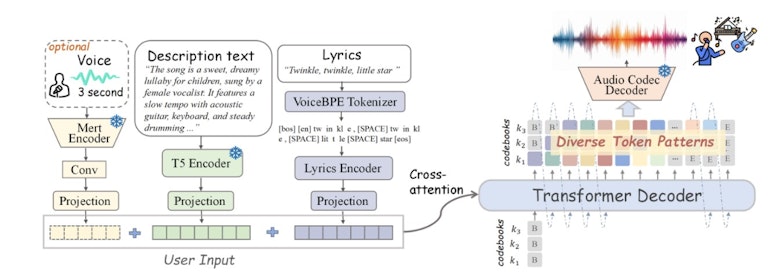
Fonctionnement général de SongGen • Source : Zihan Liu et al.
L'entraînement de SongGen repose sur un corpus de 540 000 extraits musicaux qui couvrent plus de 2 000 heures d'audio. Ce corpus a été constitué en combinant plusieurs bases de données accessibles, complétées par un processus de filtrage et d’annotation automatique pour améliorer la qualité des données.
Toutefois, cette approche soulève des difficultés, notamment en raison de la diversité restreinte des styles musicaux et des langues représentées. En conséquence, la capacité du modèle à s’adapter à des genres variés et à des textes complexes reste partiellement contrainte.
L’un des principaux défis rencontrés concerne la génération des voix chantées. En mode mixte, où l’accompagnement et les voix sont générés simultanément, SongGen parvient à produire des pistes instrumentales de qualité, mais peine à restituer des voix intelligibles et naturelles. Cette difficulté s’explique par une distribution spectrale plus instable des voix, caractérisée par des fluctuations fréquentes et un rapport signal-bruit plus faible par rapport à l’accompagnement.
Défis et limitations de la génération vocale
Pour atténuer ces problèmes, les chercheurs ont introduit une cible auxiliaire de prédiction vocale, permettant d’améliorer la clarté des paroles dans les morceaux générés. Les premiers résultats indiquent une amélioration notable de la netteté des voix, bien que celles-ci demeurent en deçà des performances obtenues avec des modèles multi-étapes. En mode bi-piste, où la voix et l’accompagnement sont générés séparément avant d’être fusionnés, les résultats sont plus homogènes, notamment en termes d’alignement temporel entre les deux composantes.
Néanmoins, l’évaluation subjective des morceaux générés révèle que les performances vocales restent perfectibles. Les erreurs phonétiques persistent, et les nuances expressives des voix demeurent limitées. Ces limitations s’expliquent en partie par le manque de données d'entraînement suffisamment diversifiées, mais aussi par les contraintes techniques du modèle actuel, qui ne permet pas encore une modulation fine du chant en fonction du texte fourni.
Un manque de données pour l'entraînement
L’une des difficultés notables de la recherche en génération de musique réside dans la disponibilité des données. Contrairement aux modèles de synthèse vocale ou d’instrumentation musicale, qui bénéficient de vastes corpus annotés, la création d’un ensemble de données adapté à la génération de chansons nécessite de coupler des enregistrements audio à des transcriptions précises des paroles. Peu de bases de données ouvertes répondent à ces critères, ce qui limite la qualité des modèles d’apprentissage.
Pour pallier ce problème, les auteurs de SongGen ont mis en place un pipeline automatisé de traitement et de filtrage des données, combinant reconnaissance vocale et analyse des structures musicales. Toutefois, ce procédé reste imparfait : la transcription automatique des voix chantées souffre encore d’un taux d’erreur élevé, notamment sur les passages complexes où la diction et l’intonation varient fortement.
Évaluation des performances
Les performances de SongGen ont été évaluées sur le jeu de données MusicCaps, en combinant métriques objectives et évaluations humaines. Les résultats montrent que le modèle génère des morceaux musicalement cohérents, avec une distance de Fréchet audio (FAD) proche de celle des enregistrements originaux. En revanche, le taux d'erreur phonétique (40,6 % dans la meilleure configuration) illustre la difficulté persistante de générer des paroles parfaitement intelligibles.
En termes de reconnaissance vocale, la similarité de timbre entre les voix générées et une référence atteint 73,7 %. Cela suggère que SongGen est capable de capter certaines caractéristiques vocales, mais reste limité dans la production d’un rendu expressif et naturel. L’évaluation subjective met également en évidence un léger manque de fluidité dans la transition entre les syllabes et les notes chantées, impactant la qualité perçue des morceaux.
Perspectives d'amélioration
Les auteurs envisagent plusieurs axes d’amélioration pour renforcer la qualité de la génération vocale. D’une part, une extension du corpus d'entraînement est nécessaire, en intégrant des morceaux dans d’autres langues et styles musicaux afin d’élargir la capacité de généralisation du modèle. D’autre part, l’optimisation du prétraitement des données, notamment en améliorant la transcription automatique des voix chantées, pourrait significativement réduire le taux d’erreur phonétique.
D’un point de vue technique, l’adoption de méthodes d’upscaling audio permettrait d’augmenter la résolution des voix synthétisées et d’améliorer leur expressivité. Par ailleurs, l’introduction de mécanismes de modulation plus fins, basés sur l’analyse des inflexions vocales naturelles, pourrait offrir un meilleur contrôle sur les nuances du chant généré. Le code et les poids du modèle étant mis à disposition de la communauté scientifique, des contributions externes pourront également contribuer à perfectionner SongGen dans les prochaines années.
Pour en savoir plus :
- Zihan Liu et al., SongGen: A Single Stage Auto-regressive Transformer for Text-to-Song Generation, Arxiv, 2025