
Les robots autonomes doivent pouvoir évoluer en équipe pour accomplir certaines tâches complexes, qu’il s’agisse de surveillance, de logistique ou encore, dans l’étude de Adam Labiosa and Josiah Hanna, de football robotisé. Pour les entraîner, les chercheurs s’appuient généralement sur des simulations reproduisant fidèlement la physique du monde réel, mais cette approche est coûteuse et chronophage. L’équipe de l’université du Wisconsin-Madison explore une alternative : l’utilisation de simulateurs abstraits, aux dynamiques simplifiées. L’objectif est de tester si des stratégies de collaboration apprises dans ces environnements virtuels peuvent être appliquées avec succès à des robots physiques.
Une alternative aux simulateurs réalistes
Traditionnellement, l’apprentissage des comportements collectifs repose sur des simulateurs haute fidélité, tentant de réduire au maximum l’écart entre simulation et réalité. Mais ces modèles sont lourds, nécessitent des calculs complexes et ralentissent le processus d’entraînement. L’approche étudiée ici repose sur l’idée que la coopération entre robots ne dépend pas nécessairement d’une simulation précise de la physique du monde réel.
L’équipe de chercheurs a utilisé un simulateur abstrait, AbstractSim, où les robots sont représentés par des boîtes rectangulaires se déplaçant sur un terrain virtuel. La dynamique des mouvements et des contacts est volontairement simplifiée : les robots avancent selon des commandes élémentaires, et les interactions avec la balle sont modélisées de manière rudimentaire. Un tel environnement permet un apprentissage accéléré – jusqu’à 30 fois plus rapide qu’avec une simulation réaliste – tout en conservant les principes fondamentaux de la prise de décision collective.
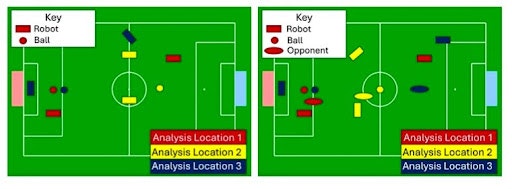
(Gauche) Tâche de football de base. (Droite) Tâche statique de défense • Source : Adam Labiosa et al.
Comment passer de la simulation à la réalité
L’un des défis majeurs de cette approche est de garantir que les stratégies apprises dans un environnement virtuel aussi simplifié puissent être appliquées à des robots physiques. Pour cela, trois leviers d’adaptation ont été identifiés.
D’abord, des ajustements de fidélité ont été apportés pour réduire l’écart entre simulation et réalité. Il a notamment été nécessaire d’adapter la vitesse de déplacement des robots simulés pour qu’elle corresponde aux capacités réelles des machines utilisées dans les tests. Un mauvais calibrage pouvait entraîner une chute de 15% à 80 % des performances lors du passage à la réalité.
Ensuite, des optimisations contre-intuitives ont amélioré l’efficacité du transfert. Par exemple, agrandir la taille des robots dans la simulation a permis d’encourager l’apprentissage de distances de sécurité plus adaptées à l’environnement physique. De même, réduire le temps de calcul empêche les agents d’adopter des stratégies erronées, comme pousser la balle au lieu de la frapper.
Enfin, l’ajout de bruit aléatoire dans la simulation a permis d’accroître la robustesse des comportements. Introduire une incertitude dans les contacts entre robots et balle a obligé les agents à apprendre des stratégies plus généralistes, leur évitant de se figer sur des comportements trop optimisés pour un environnement virtuel trop prévisible. Sans cet ajustement, les robots ne parvenaient à marquer que dans 10 % des essais en conditions réelles.
Des résultats comparables aux stratégies optimisées à la main
Pour évaluer l’efficacité de leur approche, les chercheurs ont testé leurs stratégies dans des scénarios de football robotisé, en les comparant aux comportements développés par une équipe ayant remporté la RoboCup, la principale compétition de robotique footballistique.
Deux tâches ont été évaluées : un jeu simple entre deux robots et une version avec un défenseur statique bloquant l’accès au but. Les résultats montrent que les robots entraînés en simulation abstraite ont obtenu des performances comparables aux stratégies manuellement optimisées. Sur le premier scénario, ils ont atteint un taux de réussite de 88 %, avec un temps moyen de marquage de 36,5 secondes. Sur le second, certaines configurations leur ont même permis d’égaler, voire de surpasser, les comportements issus d’années d’optimisation manuelle.
Une méthode applicable à des scénarios plus complexes
Ces résultats suggèrent que l’apprentissage par renforcement dans des environnements abstraits peut offrir une alternative viable aux approches fondées sur la simulation haute fidélité. En simplifiant les modèles et en accélérant l’entraînement, cette méthode pourrait rendre l’apprentissage plus accessible et évolutif pour un large éventail d’applications robotiques.
Les chercheurs comptent étendre leur approche à des scénarios plus complexes, impliquant des équipes plus nombreuses et des adversaires actifs. L’un des défis sera d’adapter cette stratégie aux interactions dynamiques et imprévisibles des compétitions robotiques, un domaine où l’incertitude et l’adversité jouent un rôle clé.
Pour en savoir plus :
- Adam Labiosa et al., Multi-Robot Collaboration through Reinforcement Learning and Abstract Simulation, Arxiv, 2025