
L'émergence des modèles de langage multimodaux (LMM) a ouvert de nouvelles perspectives dans la compréhension et le traitement des données visuelles et textuelles. Pourtant, leur capacité à raisonner efficacement reste insuffisamment explorée. C’est l’objectif du benchmark MME-CoT, qui évalue pour la première fois la performance des LMMs en chaîne de raisonnement (« Chain-of-Thought » ou CoT). Cette approche consiste à structurer la réflexion des modèles en plusieurs étapes logiques avant d’aboutir à une réponse.
MME-CoT comprend 1130 questions pour tester les LMM dans six domaines distincts : mathématiques, science, reconnaissance optique des caractères (OCR), logique, espace-temps et scènes générales. Plutôt que de se contenter d’un simple résultat final, l'évaluation décompose les réponses en plusieurs métriques : la qualité du raisonnement (à travers la précision et le rappel des étapes-clé), la robustesse (à savoir si CoT améliore la compréhension sans nuire aux tâches de perception), et l'efficacité (évaluant si les réflexions intermédiaires sont réellement pertinentes).
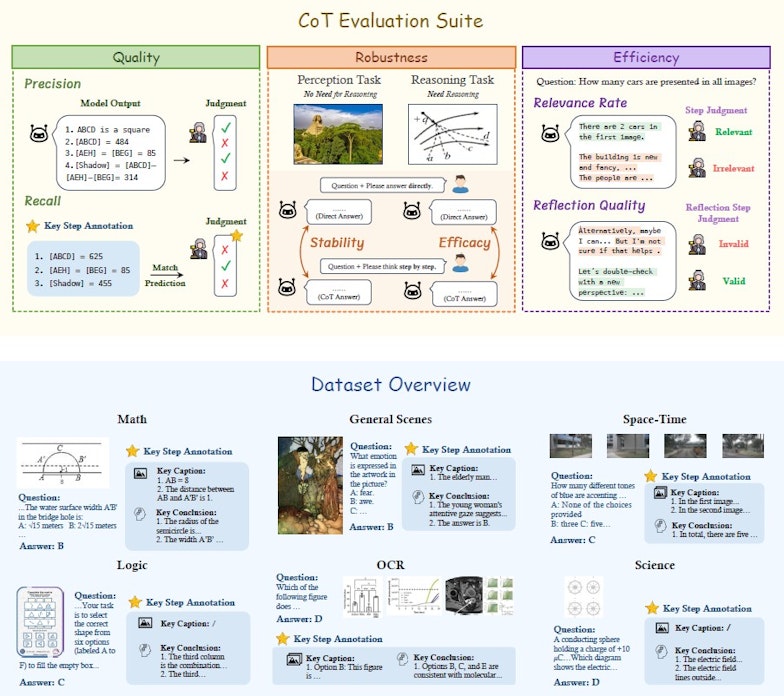
Vue d'ensemble du benchmark MME-COT • Source : Dongzhi Jiang et al.
Des performances contrastées selon les modèles
Les résultats dévoilent plusieurs enseignements notables. D'abord, les modèles avec un mécanisme de réflexion interne, comme Kimi k1.5, surpassent GPT-4o en termes de qualité du raisonnement, avec un F1 score de 64,2 contre 64,0. Cependant, leur efficacité pose question : environ 25 % des étapes de réflexion sont jugées inutiles, car elles n’améliorent pas la réponse finale. Autre surprise, le raisonnement en chaîne semble parfois nuire aux performances des tâches de perception. InternVL2.5-8B perd ainsi 6,8 % de précision lorsqu'une chaîne de pensée est appliquée aux tâches de reconnaissance visuelle, traduisant un possible phénomène de « sur-analyse » qui nuit aux performances.
Les tendances observées montrent que la taille des modèles joue un rôle clé : les LMM dotés de plus de paramètres obtiennent de meilleurs scores en logique et mathématiques. Qwen2-VL-72B, par exemple, dépasse de 2,4 points son petit frère Qwen2-VL-7B sur la pertinence du raisonnement. Cependant, un grand nombre de modèles n’exploitent pas toujours efficacement leur capacité à raisonner : un manque de concentration est souvent observé sur les tâches générales, avec un taux de contenu non pertinent variant entre 30 et 40 % dans les réponses des modèles générant des chaînes de raisonnement plus longues.
Des échecs récurrents dans le processus de réflexion
L’étude met aussi en avant des échecs récurrents dans le processus de réflexion. Environ 76 % des erreurs sont liées à une réflexion inefficace, c’est-à-dire une tentative de correction qui ne résout pas le problème. Les autres fautes relèvent de l’incomplétude (17,3 %), de la répétition sans apport nouveau (4,9 %) et, plus rarement, d’une interférence où le modèle s'éloigne d'une bonne réponse par un raisonnement erroné (1,8 %).
Les limites et perspectives du raisonnement en chaîne
Si MME-CoT met en évidence l’intérêt du raisonnement en chaîne, il souligne aussi ses limites. La longueur excessive de certaines explications peut nuire à l’efficacité des modèles et introduire des éléments non pertinents. De plus, les modèles avec réflexion, bien que plus performants, montrent une inefficacité notable dans la gestion des étapes intermédiaires.
Les chercheurs soulignent que l’optimisation de la qualité des étapes intermédiaires et la réduction des réflexions inutiles constituent les principaux défis pour l’amélioration future des LMMs. MME-CoT constitue ainsi un point de départ essentiel pour le perfectionnement du raisonnement multimodal, avec pour objectif de concilier précision et efficacité.
Pour en savoir plus :
- Dongzhi Jiang et al., MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency, Arxiv, 2025