")
Quels mystères cache le projet Strawberry, lancé dans la nuit de jeudi à vendredi dernier, sous le nom GPT o1 ? Une version bien plus coûteuse que GPT-4o, qui s'explique notamment par sa capacité à répondre à des questions plus complexes, grâce notamment à son intégration de la méthode d'apprentissage par renforcement.
L'une des principales caractéristiques de GPT o1 réside dans sa capacité accrue de compréhension et de génération de langage naturel. Le modèle offre en effet une interprétation plus fine des nuances contextuelles, ce qui permet des réponses plus précises et adaptées à des échanges prolongés. Cette amélioration est particulièrement marquée dans des situations où la continuité et la cohérence des conversations sont essentielles. GPT o1 peut ainsi maintenir une meilleure cohésion sur des dialogues complexes et prolongés.
Comprendre le texte et les images
Une autre avancée importante réside dans les capacités multimodales de GPT o1. Contrairement aux précédentes versions, ce modèle peut désormais intégrer et traiter simultanément des données de différentes natures, du texte comme de l'image. De quoi ouvrir la voie à des applications interactives plus riches, notamment dans les domaines de la réalité virtuelle et des médias numériques. Par exemple, dans le domaine de la création de contenu ou du divertissement, GPT o1 permet une interaction plus fluide entre l’utilisateur et l'IA en combinant plusieurs types d'informations en temps réel.
Côté sécurité, OpenAI a renforcé les mesures éthiques et de protection intégrées dans GPT o1. Des mécanismes avancés ont été mis en place pour atténuer les biais potentiels et garantir une utilisation responsable de l'IA. Cela inclut une surveillance continue du modèle pour identifier et corriger toute déviation ou problème éthique. En outre, OpenAI donne aux utilisateurs la possibilité de personnaliser le comportement de l'IA en fonction de leurs propres exigences éthiques.
L’IA qui performe aux olympiades…
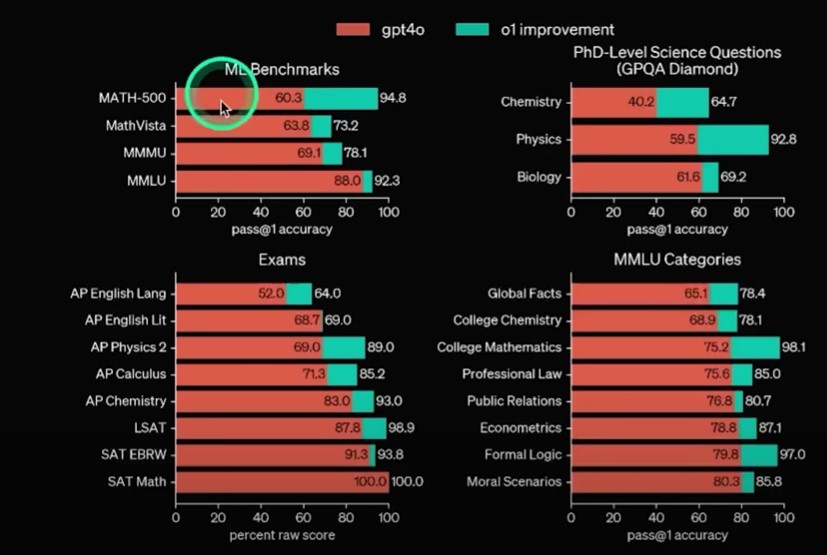
Les progrès de GPT o1 (Source : Matthew Berman)
Contrairement à son prédécesseur GPT-4o, la série o1 ne propose pas certaines fonctionnalités comme l’analyse de fichiers ou l’intégration avec des applications externes. Cependant, elle excelle dans les tâches nécessitant des compétences en raisonnement. Lors d’un test interne, o1-preview a passé un examen de qualification de l'US Math Olympiad, obtenant un score moyen de 74% à 93%, bien supérieur aux 12% obtenus par GPT-4o. Ces résultats placent o1-preview parmi les 500 meilleurs participants de l’examen.
OpenAI a également testé o1-preview sur un ensemble de questions scientifiques complexes, à savoir le benchmark GPQA Diamond, qui couvre la physique, la biologie et la chimie. Le modèle a surpassé un groupe d'experts titulaires de doctorats dans ces domaines, renforçant l’idée que o1 est conçu pour exceller dans les tâches nécessitant des compétences en réflexion scientifique.
… et au déchiffrage de textes cryptés
Le modèle o1 utilise une approche qui le fait "penser étape par étape", appliquée à la fois lors de la phase d'entraînement et pendant l'inférence (le génération de réponse). Cette méthode est connue sous le nom de "chain-of-thought" (chaîne de pensée ou COT). Contrairement aux modèles de langage classiques, qui produisent des réponses de manière linéaire et sont donc plus susceptibles de commettre des erreurs successives, o1 évalue chaque étape du raisonnement : une tâche qui était réservée, jusqu’à présent, au prompt engineer. Le modèle ajuste ensuite ses réponses en fonction des résultats intermédiaires. Ce processus itératif lui permet de corriger ses erreurs au fur et à mesure, améliorant ainsi sa précision pour des tâches complexes.
Cela améliore considérablement la précision des réponses du modèle, en particulier sur des questions exigeant une décomposition logique. OpenAI a perfectionné cette technique de COT via l'apprentissage par renforcement, un processus qui aide les modèles à s'améliorer au fil du temps en recevant des retours positifs pour chaque tâche résolue correctement.
Une des démonstrations les plus marquantes de cette capacité est la résolution d'un texte brouillé. Lors d’un test interne, o1-preview a réussi à déchiffrer une version brouillée de la phrase "Il y a trois R dans Strawberry" – devenue iconique dans le folklore de la Silicon Valley – , en suivant une logique qui nécessitait de nombreux ajustements en cours de route.
En outre, cette nouvelle approche rend le modèle plus sûr. OpenAI a mené une série de tests de sécurité avant de déployer GPT o1. La capacité de raisonnement en chaîne logique a contribué à des améliorations notables en la matière. Cela permet au modèle d’offrir des réponses plus fiables et mieux encadrées, réduisant les risques de comportements imprévus.
Un raisonnement sans cesse validé
Le modèle GPT o1 s’appuie ainsi sur un mécanisme appelé "Process-supervised Reward Model" (PRM), qui évalue la validité de chaque étape d’un raisonnement plutôt que de simplement fournir une réponse finale. Pendant la phase d’entraînement, des annotateurs humains attribuent une évaluation à chaque étape d’une solution, avec des labels indiquant si l’étape est correcte, incorrecte ou ambiguë. Ce processus permet à l'IA d'apprendre non seulement à donner la bonne réponse, mais aussi à comprendre le raisonnement sous-jacent, en corrigeant ses erreurs au fur et à mesure.
Ce modèle PRM renforce la capacité de GPT o1 à mieux généraliser dans des contextes inédits. En se concentrant sur la justesse du raisonnement, o1 affine sa démarche lors de l'inférence, en générant des étapes intermédiaires qui sont ensuite vérifiées et corrigées si nécessaire. Cette approche permet de réduire les erreurs répétitives et de rendre le modèle plus efficace pour des tâches complexes, notamment dans les domaines des mathématiques et du codage, où chaque étape du processus est cruciale pour la réussite finale.
Une nouvelle vision de l’inférence
GPT o1 introduit également une nouvelle approche dans le domaine de l'inférence, où la précision des réponses peut être améliorée en augmentant les ressources de calcul disponibles. Contrairement aux modèles autorégressifs traditionnels, où plus de puissance de calcul sert uniquement à accélérer la génération des réponses, GPT o1 utilise un processus itératif qui permet d'explorer plusieurs pistes de raisonnement en parallèle. En allouant plus de temps et de capacité de calcul à une tâche, o1 peut réviser et ajuster ses réponses en fonction des résultats intermédiaires, réduisant ainsi les erreurs au fil du processus.
Ce nouveau paradigme affecte la manière dont les performances des modèles d'IA doivent être mesurées. Avec GPT o1, plus de calcul ne signifie pas une réponse plus rapide – le modèle est au contraire beaucoup plus lent –, mais une meilleure qualité de réponse, en particulier pour les tâches complexes nécessitant des raisonnements multi-étapes, comme les puzzles ou les problèmes mathématiques.
Plus de calcul, plus de ressources
La série o1 est disponible via ChatGPT et par le biais d’une interface de programmation (API), permettant aux développeurs et aux entreprises de l’intégrer dans leurs applications. Pour utiliser GPT o1, il faudra payer 15 dollars par million de tokens en entrée, et 60 dollars pour un millions de tokens en sortie. Une somme entre 3 et 4 fois supérieure au coût de GPT-4o.
La version o1-mini, plus légère, est proposée à un prix d’inférence 80% inférieur à celui de o1-preview, bien que sa base de connaissances soit plus restreinte. Ce modèle allégé est particulièrement performant pour des tâches de programmation. OpenAI prévoit d’intégrer o1-mini dans la version gratuite de ChatGPT, tout en augmentant progressivement les limites d’utilisation pour les abonnés aux versions payantes. À son lancement, les utilisateurs peuvent soumettre 30 requêtes par jour à o1-preview et 50 à o1-mini.
Pour en savoir plus :